![[Pandas] 2. Dataframe 파일 저장 및 열기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbfzMrw%2FbtsFRavmxRE%2FNZXFkeF9VOHL9Bc6sCWRpK%2Fimg.png)
아래 글에서 소개한 것처럼, 우리는 흔히 CSV 파일을 얻을 수 있습니다. Pandas에서는 CSV 혹은 Excel 파일을 어떻게 열고 활용할까요? 앞선 글에서 만든 데이터들을 어떻게 저장할까요?
[파이썬] CSV 라이브러리 사용해보기
저에게 만큼은 찾아오지 않을 것 같던 취준 시즌도 마침내 왔습니다. 그리고 삼성전자 인턴직무 자기소개서 문항을 보고 혼란에 빠졌습니다. 엔지니어 관련 프로젝트를 쓸 게 없더군요. 깔끔하
senti-mech.tistory.com
이번 글에서는 Dataframe 을 CSV, Excel(xlsx), txt 파일로 저장하고, 읽어오는 법을 소개합니다.
* 본 글은 위 영상을 참고합니다.
1. csv, txt, xlsx 로 저장하기

우리가 사용했던 자료입니다. 이걸 csv와 txt로 저장해봅시다.
A. csv 로 저장하기
df.to_csv('score.csv', encoding = 'utf-8-sig', index=False)
# Encoding 없을 시 엑셀로 열면 글자가 깨질 수 있습니다.
# index = False 라면, 기존의 인덱스 '지원번호'가 사라진 채 데이터만 나옵니다.
B. 텍스트(.txt) 파일로 저장
df.to_csv('score.txt', sep='\t') #데이터 간 구분을 탭으로. 만약 sep='+' 를 넣으면 + 가 됩니다.
sep 으로 탭을 넣었을 때와 +를 넣었을 때입니다. 텍스트는 해봤는데 안되더군요.
C. 엑셀(.xlsx) 파일로 저장
df.to_excel('score.xlsx')
너무 간단한 것들이라 따로 할 말이 없습니다.
2. csv 파일 열기 (skiprows, nrows)
df = pd.read_csv('score.csv', skiprows=[1,3,5,7,8]) #그냥 2를 넣으면 제일 위 2줄 스킵
df
Skiprows 를 이용해서 원하는 행만 가져올 수 있습니다. 그냥 숫자를 넣으면, 그 갯수만큼 뛰어넘고 가져옵니다. 위 코드처럼 집합을 넣으면 그 순서의 행들만 스킵합니다.
df = pd.read_csv('score.csv', nrows=3) #지정된 갯수 만큼만 row 가져옴
df
nrows 는 원하는 갯수만큼만 가져오게 해주는 명령어입니다. 두 개를 조합하면, 앞의 몇 행을 뛰어넘고 그 때부터 몇개의 행을 가져올 수 있겠죠?
3. 텍스트(.txt) 파일 열기
df=pd.read_csv('score.txt')
df
음... 아까 sep='+'를 한번 실험해봤더니 이런 일이 벌어졌습니다. 이 데이터가 +로 구분된다는 걸 아니까, 이용해봅시다.
df=pd.read_csv('score.txt', sep='+')
df
이제 잘 나오는군요. csv 파일이 비록 comma seperated value 파일이긴 하지만, 다른 기호로 데이터가 구분되어도 잘 가져올 수 있겠습니다.
그런데 우리는 지원번호를 index로 넣었었는데, 이게 그냥 데이터로 빠져버렸습니다. 이걸 index로 넣어봅시다.
df=pd.read_csv('score.txt', sep='+', index_col='지원번호')
df
index_col 을 통해 원하는 Column을 index로 만들 수 있게 되었습니다. 당연히 지원번호 대신 이름을 넣으면 이름이 index가 됩니다. 아래처럼 따로 명령어를 사용해 index를 설정할 수도 있습니다.
df=pd.read_csv('score.txt', sep='+')
df.set_index('이름', inplace=True)
df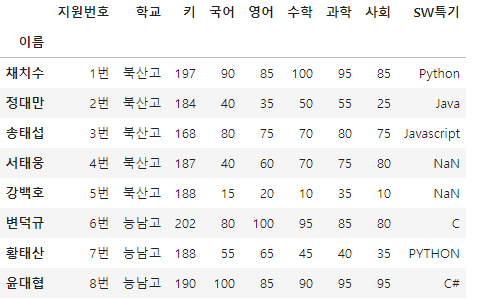
인덱스를 이번에는 이름으로 설정해봤습니다. 잘 바뀌었네요. inplace 안쓰시면 안바뀝니다...!
4. 엑셀(.xlsx) 파일 열기
df= pd.read_excel('score.xlsx', index_col='지원번호')
이렇게 치면 위에 다른 사진들처럼 잘 나옵니다. 인덱스는 지원번호가 되겠죠?
제가 이런 걸 배울 때 강의와 다른 것들을 자꾸 시도해보는 편입니다. 그래서 조금 어지러울 수 있다는 점 양해 부탁드립니다,,,^^