![[Python] 산점도 (Scatter Plot) 그리기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbdhVIS%2FbtsGiz2viHA%2FfxHQsoKZXNpqU0hJSv9dXk%2Fimg.png)
[Python] KNN으로 데이터 분류하기 (with Scikit-Learn)
[Pandas] 6. 폴더 내 여러 데이터 프레임(파일) 합치기 [Pandas] 5. 조건에 맞춰 데이터 추출하고 수정하기 (Kaggle 에서 가져온 Gear Defection 데이터 이용) Kaggle 이라는 사이트가 있습니다. 데이터 사이언
senti-mech.tistory.com
지난 글에서 나는 다짜고짜 KNN을 이용하였다. 그 결과, 신뢰도가 50%라는 도박성 짙은 모델이 만들어졌다. 데이터가 잘못됐거나, KNN이 데이터에 맞지 않는 모델일 수 있다. 그걸 알기 위해서 산점도(Scatter Plot)를 찍어 데이터의 분포를 먼저 알아보자.
1. 기존에 알던 방법 : df.plot()
import pandas as pd
df=pd.read_csv("total.csv")
df.plot(x='sensor1', y='sensor2')
내가 원한건 그냥 점을 찍어주는 거였는데... 알아서 선형보간 (Linear regression)을 했나보다. 나는 점을 찍는 방법이 필요했다.
2. 첫번째 방법 : plt.scatter() 이용하기
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_csv("total.csv")
plt.scatter(df['sensor1'],df['sensor2'], s=5, c='orange', alpha = 0.5)
#각각 x축, y축, 사이즈, 색깔, 투명도
plt.xlabel('x axis') #x축 라벨
plt.ylabel('y axis') #y축 라벨
plt.show()
됐다. 점을 찍었다. 아... 근데 각 Defection 별로 색깔이 다르게 나왔으면 하는데... 좋은 방법이 없을까?
3. 조언 받은 방법
x1 = df['sensor1'].values # 센서 1의 데이터
x2 = df['sensor2'].values # 센서 2의 데이터
y = df['gear_fault_desc'].values # 디펙션 데이터
label = list(set(y)) #집합을 리스트로 바꾸어 유니크한 값만 뽑아오기
idx1 = np.where(y == label[0]) # y에서 첫번째 디펙션 가진 데이터 인덱스 가져오기
idx2 = np.where(y == label[1]) # 이하 반복
idx3 = np.where(y == label[2])
idx4 = np.where(y == label[3])
idx5 = np.where(y == label[4])
idx6 = np.where(y == label[5])
idxs = [idx1,idx2,idx3,idx4,idx5,idx6] # 그 인덱스 리스트들을 리스트 안에 넣기
plt.figure(figsize=(10,10),dpi=600) #figsize는 인치 단위, dpi 지우면 속도 빨라짐
for index, lbl in zip(idxs, label):
plt.plot(x1[index],x2[index],'.',label=lbl)
plt.legend() # 범례
plt.show()
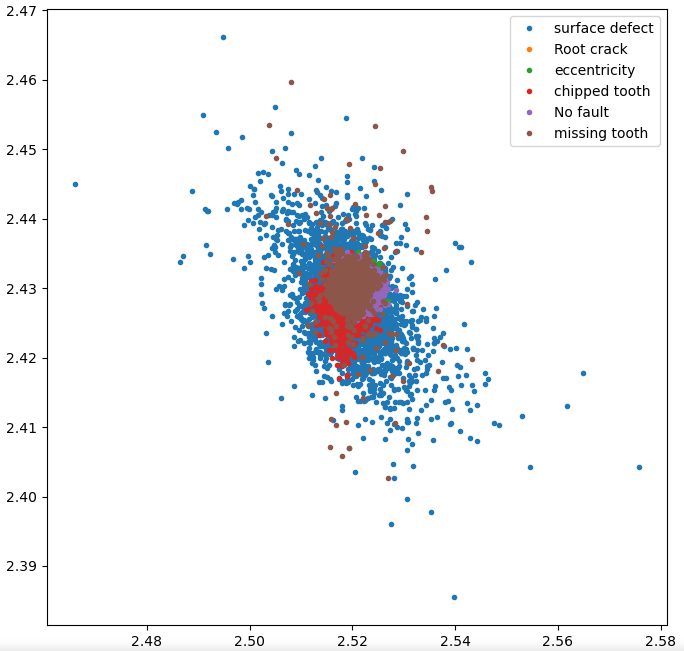
와우. 됐다. 여기서 못보던 함수들이 몇가지 있다.
a. set()
집합으로 만들어주는 함수다. 예를 들어 [1,2,2,3,3,3] 이란 리스트가 있다고 하자. 이걸 set 함수를 통해 집합으로 만들면 {1,2,3} 이 출력된다. 집합에는 순서가 없다는 점 참고. 첫번째 원소 호출 같은게 안된다.
list(set())을 하면 그 집합을 리스트로 반환한다. df.unique() 와 비슷한 느낌이 있다.
b. zip을 이용한 반복문
zip() 함수를 이용하면 반복문의 인자를 두 개 이상 활용할 수 있다. 아래 예시처럼.
a = ['김', '이', '박', '최', '나']
b = ['범수', '수', '효신', '백호']
for last_name, first_name in zip(a,b):
print(last_name, first_name)
# 결과값 : 김 범수, 이 수, 박 효신, 최 백호결과값에 '나'는 보이지 않는다. 이는 하나의 리스트에서 원소가 매진(?)되면 더 이상 작동하지 않는 것을 의미한다.
c. np.where()
np.where() 함수는 괄호 안의 조건에 맞는 데이터의 인덱스를 가져온다.
위 코드에선 defection 을 찾아서 인덱스를 가져온 것이다.
그래서 저 코드를 종합하면 다음과 같다.
데이터를 각각의 변수에 집어넣고, 분류할 클래스인 defection 데이터를 set 함수를 이용해 중복값을 모두 제거했다. np.where을 통해 defection 별로 데이터의 인덱스를 분류한다. 분류된 인덱스를 반복문으로 plot 한다.
그래프를 통해 확인하니, 이 데이터로 신뢰도를 올릴 수 있는지 의문이 들었다. 하지만 또 궁금해진 것은 노이즈 필터링이다. 통계학에선 아웃라이어(이상치)라고 부른다고 했다. 그래프를 보면 중심에서 동떨어진 점들을 필터링 하는 방법이 있으면 더 좋을 듯했다. 이상한 값들을 제거함으로써 모델의 신뢰성을 올리는 과정을 '데이터 전처리'라고 한댄다.
이에는 결측치와 아웃라이어 처리, 정규화 등이 있다는데 한번 찾아볼 예정이다. 다음 글은 이거다.